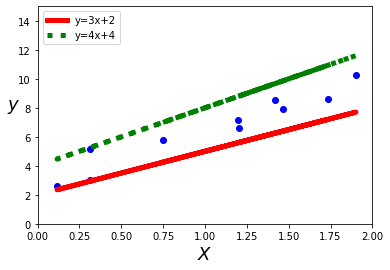
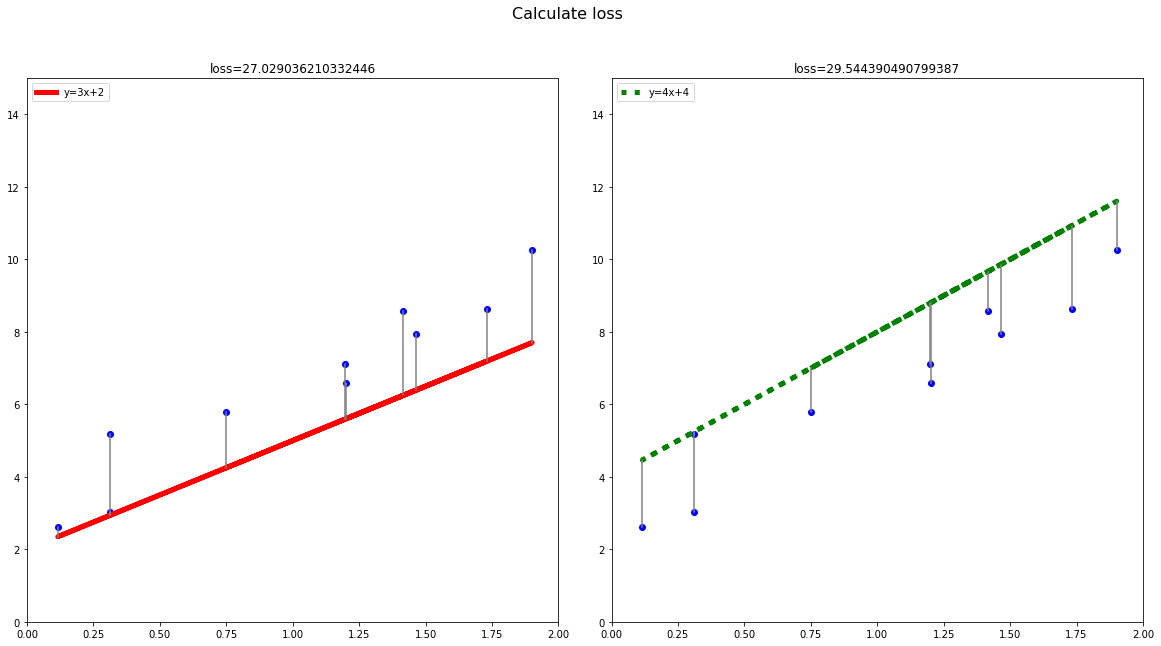
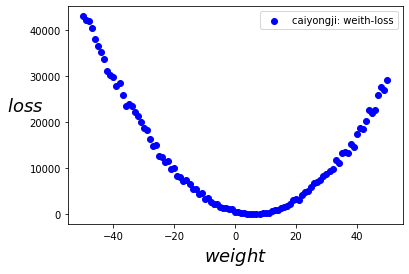
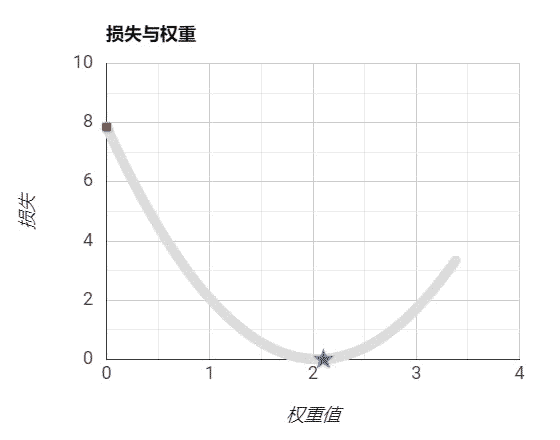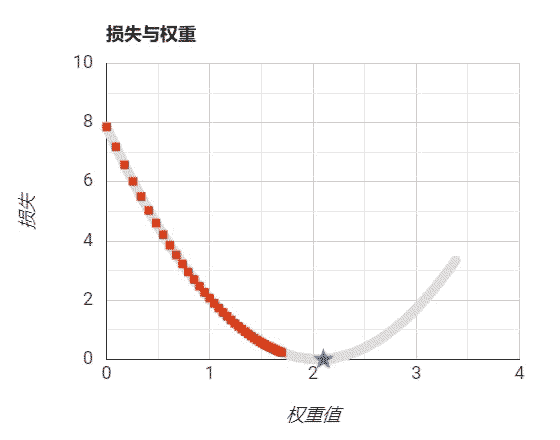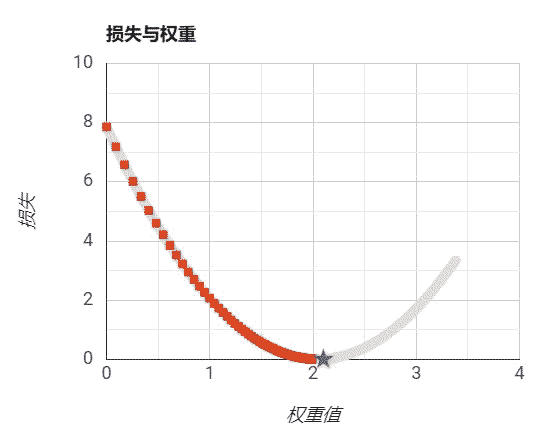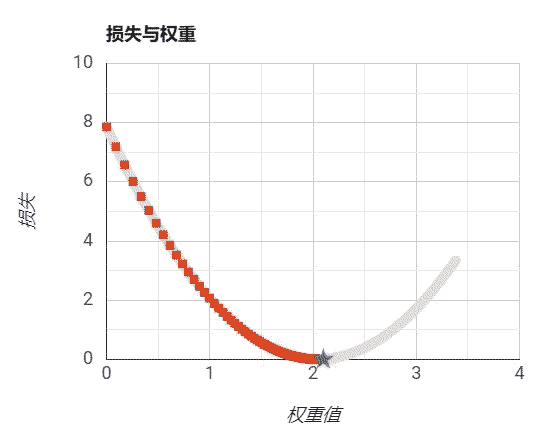
如果我们不能击败它,就必须与之共存。
随便聊聊。文末有红包🧧现金💰书籍📖赠送。
新冠病毒正在彻底改变世界,人类与之斗争,没有人敢断言结果。我们做职业规划、人生规划时,要重新考虑风险。
中国崛起
IMF预计,中国是2020年全球唯一一个经济正增长的主要经济体。
中国在悠悠的历史长河中,一直不是以民主为核心的。我们受孔孟思想的影响深远,我们尊师重道,信仰真理,追随权威。当面对灾难时,这尤其有效,我们让最有能力的人做决定,听从他的一切指挥,脱离困境。这是人民出让权力,政府执行软强制主义的典型方式。它显然比所谓的“可操控的民主”更高级,更何况随着社会的进步,中国在一点点将人民的权力归还给人民。这种信任让中国人比任何国家都团结,我们认准的方向,都是无人能挡的,无论对错。
这让中国的拳头是最硬的。
当然中国有中国的问题,但无疑我们不该忽略中国巨大的优势。疫情前很多有钱的朋友在讲海外资产配置,现在在考虑把热钱留在中国。我想很大的原因就是因为中国更安全。我听说某个F家的朋友一直远程办公,2020年初去三亚度假,然后全年在三亚工作(度假)。
行业变化
谈生活之前不得不谈行业。
虽然很多传统行业不得不需要线下人员参与,但我相信我的读者大多偏向于互联网、IT、软件产业。我们有脱离线下转到线上的机会,这是我们的优势,我们可以坦然的承认这一点。
传统行业,比如农行、制造业重要吗?相当重要。但我们过了只追求吃饱穿暖的阶段了,我们有了更高的追求,我们扬帆起航追求的是星辰大海……
有人说,没人种田你们所有人都会饿死。其实不是的,这只是固守在传统行业上的人的嫉妒罢了。如果真的没人种田了,国家会有统一的、机械的、标准化的农耕方式来代替人力。这时多余的人力还是要转移到新兴的行业上去。这只是时间早晚的问题。历史的车轮没有任何人可以阻止,我们顺应着时代才能让自己过的更好。
这个世界不惩罚墨守成规的人,它会只奖励那些拥抱变化的人,渐渐地那些站在原地的人就被多数人落下了。举个简单的例子,我们不惩罚单身的人,但会给有孩子的人减免个税。
快递、外卖、远程会议,网课、网红、直播带货。 这些是2020年新钱的主要流向的典型例子。直播经济、网红经济、娱乐经济,很多人对此是嗤之以鼻的,我只是想说我们别着急否定他们,有时候困住你的恰恰是你自己的旧思想,那些条条框框。如果我说有些人一年赚到的钱是别人300年赚到的钱呢?或许他们的收入不稳定,但你能活到300岁吗?
虽然个例不代表整个行业,但它能代表行业趋势。有时候我们承认别人优秀,才能自己和自己真正地和解。
生活变化
再具体到生活谈变化。
还记得2010年的主流手机是什么?没错,10年前诺基亚还是大哥,流量1M一块钱。10年后的今天,流量1G一块钱,人们实时语音,视频通话。很多没等官方通报,视频已经在群里传飞起来了。
今年(2020年)我在的园区场地着火,先是日本的朋友发给我的消息,我才抬头看到窗外的浓烟。不查领导酒驾的交警,不戴口罩防疫的干部,不让群众使用卫生间的机关,10年前没人想到贪腐是靠互联网整治的。信息的超快速传输已经彻底改变了我们的生活。中国山区田园生活的景象可以传到纽约,我们可以看卖翡翠的演员忍痛割爱,甚至远隔万里的情侣也可以有别样的情趣……咳咳。
沟通的方式变了,购物的方式变了。我们的世界变好了也变坏了,但绝对和以前不一样了。也许有些技术并不稀奇,几年甚至几十年前就有了,但以前成本高昂,现在普及量产还可以再送你两桶都有,让普通百姓用得起了,这就很了不起。我看到一个短视频里,有学生被叫到黑板前做题,下面的同学用蓝牙耳机偷偷告诉他答案了。
我终于可以说那句话了,你的孩子生活在你永远无法想象的未来,你甚至连做梦都梦不到。
Your children are not your children.
They are the sons and daughters of Life’s longing for itself.
They come through you but not from you,
And though they are with you, yet they belong not to you.
You may give them your love but not your thoughts,
For they have their own thoughts.
You may house their bodies but not their souls,
For their souls dwell in the house of tomorrow,
which you cannot visit, not even in your dreams.
—Kahlil Gibran
拥抱变化
我表达一下我自己浅薄的看法,为了让意见有更多参考的价值,我不会说一些模棱两可却正确的话。我的表述可能不严谨、很狭隘,但应该会很直接、很有用。如果你发现我语言或逻辑上的漏洞请参考互联网上的其他知识自行判断,兼听则明。每个道理都有其有限的作用范围,也跟每个人的认知偏差有关,不能一概而论,也无需争论对错。
世界看中国,中国看北京。
随着“内循环”政策的提出,北京的地位变得更加重要,超过了长三角、珠三角经济区的地位。无疑是老大中的老大。以后北京无疑是中国天花板最高的城市。
选择城市就像爬山,在爬之前你并不知道你能爬多高,但如果你足够优秀,你在一个小山头很容易爬到山顶,当你想换一座山的时候,成本无疑是非常高的。一线城市有更多、更好的机会,它们永远有足够大的舞台让你发挥。如果不是舞台不够大,是你不够强,或者你不想去争名逐利,二三线甚至十八线城市也可以让人活得很舒服。
抛下北京不谈,我认为新的城市优先级会从南到北排序,深圳、环深圳、上海、环上海、海南。
线下转线上。
如果你有机会一定要让自己尽量的靠近线上。跟着新钱走,有机会。远离实体接触,更安全。脱离坐班,更自由。
而时间自由是实现财务自由的第一步。
线上的机会太多了,大家尽量选择门槛高的,能发挥自己优势的领域。一是避免过分竞争,杀入一片红海,生存还是很难的。二是用自己的特长、高门槛来构建壁垒,让自己有竞争力,可以持续发展,而不是一锤子买卖。
你自己独一无二的灵感。
试试呗?加油。
AI未来
目前,人工智能非常适合简单的、重复性的工作。
AI在医学领域有大量的应用,但它无法代替医生,很长一段时间内都不可能。AI在自动驾驶领域有高速的发展,但它无法代替司机,小范围的有限条件下后续可以,但无法普及。AI还没有强大到代替专业的人,但它可以做为辅助手段帮助专家,节省专家的精力。
在可以预见的未来,AI会取代那些低技术含量、做重复工作的劳动力。理由很简单,AI不用保险、AI不会抱怨、AI不用休息,无需年假、奖金。AI稳定且高效,它不会因为与老婆吵架而工作不在状态,也不会因为连续工作24小时而效率下降,甚至AI可以在毫秒级内做出人类无法做出的连续反应。
比如公务员、银行职员。目前很多大银行推出的无人银行的概念已经足够说明了,这点我就不具体说了。说说公务员,我指的是公务员中那些技术含量低的工作,也就是那些所谓的钱多事少的工作。越是容易的、简单的工作越容易被取代,以后追求稳定可以,太清闲就别想了,提升自己的一技之长才是正道。我为什么这么说呢,因为我已经见到有AI公司和政府部门洽谈合作了。
(注意:每种职业都有不可替代的努力的、勤奋的人,我尊重每一个职业。上文单单指价值产出少,可替代性强的工作内容。)
打工人还是打工人,工具人终被工具替代。
拥抱AI
其实你问问中国最优秀的那批人,世界将会怎样?他们也不知道。唯一可以确定的是,没人可以阻挡世界的发展,除了顺从你别无选择。AI正在取代一些人的工作,虽然残酷,但这是事实。
有人觉得AI是博士、研究生从事的行业,至少要有计算机,数学的背景。一提数学就头大。其实大可不必。2020年5月,韩国TFUG邀请谷歌的AI主管Laurence Moroney进行了一次采访,我有幸听到他对AI的看法,我这里简单翻译下他的意思,并不是他的原话。
很多人害怕数学,害怕大量的深度的微积分知识。其实我们可以实现编码而不考虑数学,我们可以使用TensorFlow中高(层)级的API,来解决问题,如自然语言处理,图像分类,计算机视觉序列模型等而无需理解深刻的数学。就像你使用JAVA却不一定非要掌握它是如何编译的。未来,AI只是每个开发者技术栈(toolbox)中的一部分,就像HTML, CSS, JAVA。
参考Youtube 4分06秒:https://www.youtube.com/watch?v=8kMaqQNubNA
其实,对于先避开数学接触机器学习,再试着深入了解原理,这种方式我是非常认可的。我们不见得要跑到所有人的最前面,我们勇敢的往这个方向走就可以了。先当“调包侠”如果有机会再当“调参侠”也是不错的选择。
我正在写这方面的教程,我的方式就是先避开数学,先看看机器学习究竟长什么样,再去深入它的理论。大家可以关注我,公众号【caiyongji】,2021年我会不断的更新AI方向的原创文章,包括人工智能科普、机器学习教程。
说回新冠
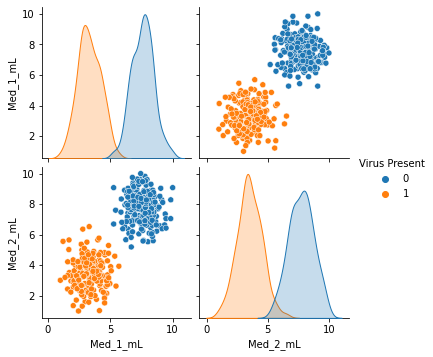
早在2月份的时候我看了朋友给我发的关于新冠病毒的论文,它和艾滋病有着某种程度的相似,我想了想最近几十年来医学界在艾滋病领域的发展,说实话,我是悲观的。随着欧洲病毒的变异,我想我们真的需要认真对待,做好与之长期相处的准备。世界正在改变,2021年的新世界,我们要顺应新的规则。先保护好自己,再来爱这个世界。
爱惜自己
大家可以选择996,但一定要记得爱惜自己。我们不知道明天和死亡哪个先来。
我们要学会使用工具,而不是把自己变成工具。在工作中,大家要学聪明一点,不要做那些低价值的重复性的工作,也就是说,少做打杂的工作让自己沦为工具人。要想着在工作中,哪些技能是你能带走的,自己能带走的本事才是真的本事。历练自己,就是要挑着那些能带走的技能历练,不要挑那些谁都能干的任务,不要把自己当作一颗螺丝钉。
有人可能会说,这样会不会太自私了?兄弟,我巴不得你们自私一点,你可以为了自己拼命,可以为了家人拼命,唯独不要为资本拼命。某种程度上来说,为资本拼命害人害己。
中国每天都在有造富的神话,让人们都心浮气躁了。其实你看的新闻全都是小概率事件。新闻之所以是新闻,正是因为它不常见所以人们才爱看。你身边整天充斥的消息,并不是这个世界的真相。
有些人不信命,总想带着天涯海角的辽阔期待着一个奇迹。我劝大家不要相信奇迹,相信什么自己是天选之人。我说的命不是指命运,而是指你能力的上限。 我们要做那些大概率成功的事情,而不是去搏一个小概率。中国教育真正牛的地方在于,它能把那些资质平庸的人培养成可用的人才,让那些没有天赋的人也有机会展示自己。
我不是叫你不去努力,努力可以,但要留有退路。不要跟自己较劲,更不要透支自己的一切去赌明天。稳步向前,别急。
珍惜眼前,跟自己和解。
祝福
我祝你2021年一切顺利!新年快乐!
本文同步于公众号【caiyongji】,原文文末有红包🧧现金💰书籍📖赠送。
]]>